I mean it. I’ll go back to VSCode! I’ll even work in a browser on JupyterLab!
I love DataSpell. Or the idea of it anyway. It’s billed as “The IDE for Data Scientists”, and it (mostly) lives up to this name. Through my years I’ve seen all kinds of Jupyter solutions, including barebones on a private box that was WAY too cool for someone of my pay grade (ask me how you compile gcc-5.x on RHEL without any tools that have been updated beyond 2005. Actually don’t, that’s a bad conversation starter), semi-managed installations on a much more appropriately-sized instance, fully customized internal solutions built by a small army of EEs to integrate perfectly with one of the world’s largest machine learning workflows, and, well, Databricks.
I’ll give you a hint: Databricks blew them all away. (Sorry bento!)
But aside from medium-to-large data workflows that demand that kind of hardware, there’s a large gulf of space in the “laptop notebook” world, with an endless collection of IDEs and things that are objectively better but I’m too dumb to use them properly, and some of these solutions are just far superior than cloud-based solutions that run in a web browser (in terms of usability).
The main usability gains of an IDE in no particular order:
- Full plugin support for interacting with non-notebook code
- Git integration
- Incredible customizability
- Especially keyboard shortcuts. Ever tried to use emacs keybindings on a browser-based application? Yeah, it’s not a good time.
And from a high level, DataSpell nails all of these. It’s got a kick-ass built-in environment manager, allows you to seamlessly switch between .ipynb, .py, .json, or whatever you need to edit. And yes, it handles R pretty well. I’m told as much anyway.
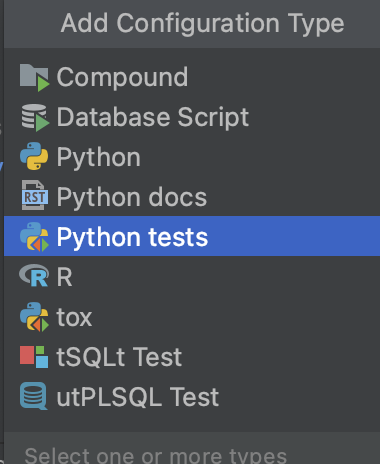
Check it out! GUI first-party tox support? PyCharm users may already know about this, but as someone who was coming from VSCode, this kind of integration was just about the smartest thing you could put into one of my IDEs. Countless data scientist work-hours have been spent doing battle with tox in a terminal while trying to fix airflow DAGs or other similar job code objects.
But if the ambition and the scope gets you excited, it’s the implementation of these features that is the ultimate letdown. There’s simply a huge number of small, annoying bugs throughout this product. That tox configuration? Yeah, it’s just DOA from the moment I started up DataSpell to write this post.
What really broke me recently, however, was Git integration. Git is a thorny issue for data scientists, because it’s become synonymous with context-switching. We must often move between a journeyman’s understanding of git and the peculiarities of an organization’s pre-commit and push githooks when editing, say, a pipeline job. But when we switch back to our notebooks, there’s snag after snag.
The debate on how to properly version control data science artifacts goes back to the earliest days notebook software itself. Indeed, while Jupyter dates back to 2014, one of its many spiritual predecessors, SageMath, was released only a month or so before Git. Jupyter notebooks, like SageMath, initially had a primarily single-user intended use-case. A lonely graduate student, hacking away at a difficult tensor calculus project, or some numerical simulation of fish inside of a large container: this was the audience for these early notebook products. These kinds of projects not only weren’t collaborative to begin with, but in many cases they had externalities that actively refused collaboration. The amount of time and background required to explain not only the problem itself, but how the code works (one needs only ask 2-3 people in any STEM department about how good the coding standards are amongst their graduate students) both posed a huge barrier to the kind of distributed, open-source development that became increasingly common in the early 21st century.
But we’re no longer lonely graduate students sitting in windowless offices. Jupyter (and even SageMath, which now just uses Jupyter as a backbone) has grown up and now occupies critical toolbox space in virtually every company that’s serious about data science. The decision to adapt mainstream version control practices to this technology has many pain points, not least of which is the fact that Jupyter saves outputs along with code cell contents, all in a JSON-formatted specification. This makes reading diffs a huge PITA.
Anecdotally, I probably field 2-3 git-related questions a week during $DAYJOB. We even snagged a DE to write us some awesome githooks that helped us integrate both our notebooking solution and our git repo solution in a more seamless manner. We’ve probably pinged our sales rep about this issue at least a dozen times.
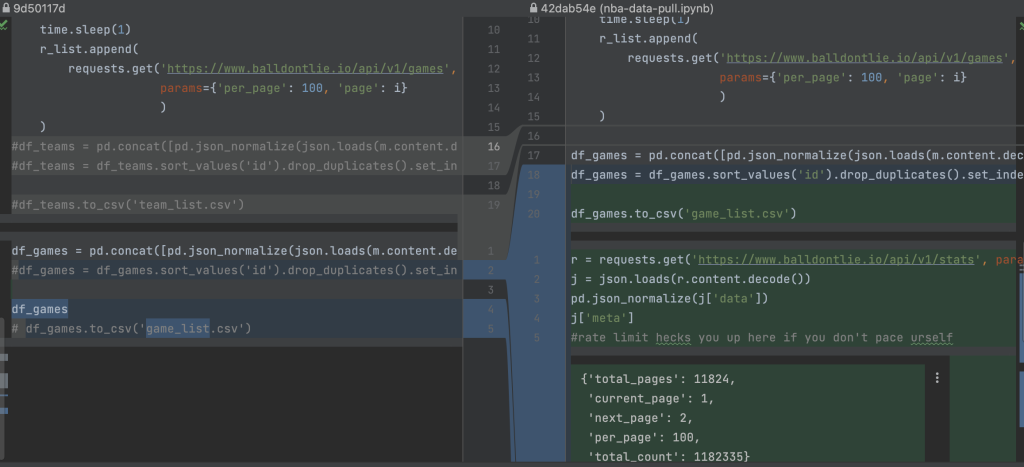
I say all this to say the following: Doing version control correctly in many common DS workflows is a hard problem. A problem which I was downright excited for DataSpell to blow me away with. Just take a look at this diff viewer:
And compare that to this one, on Github.
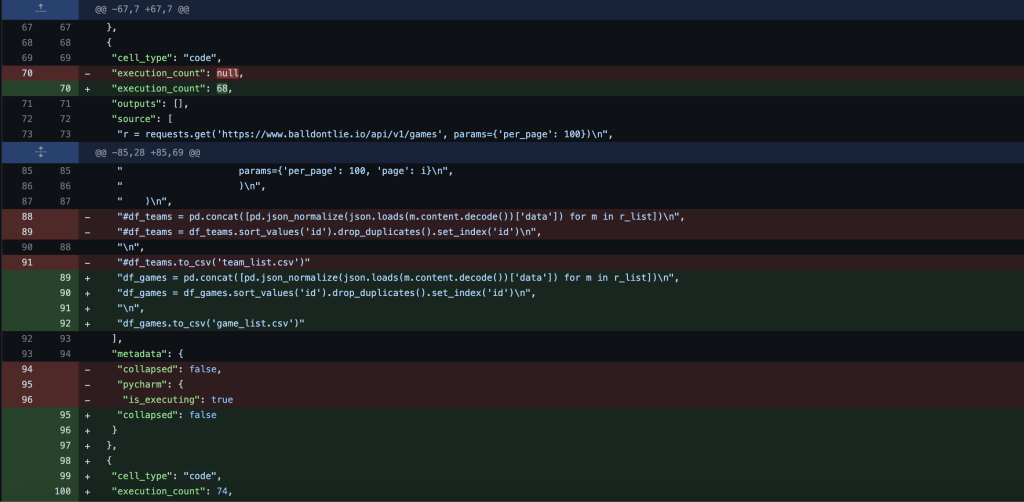
You can see that a lot of extra stuff gets thrown in there. This means it’s possible to unknowingly stage and commit changes that don’t actually have any real differences. Simply re-executing the code without a change will create an unstaged change on disk when the file is saved!
There’s even more extreme examples, like this one from reviewnb’s project maintainers:

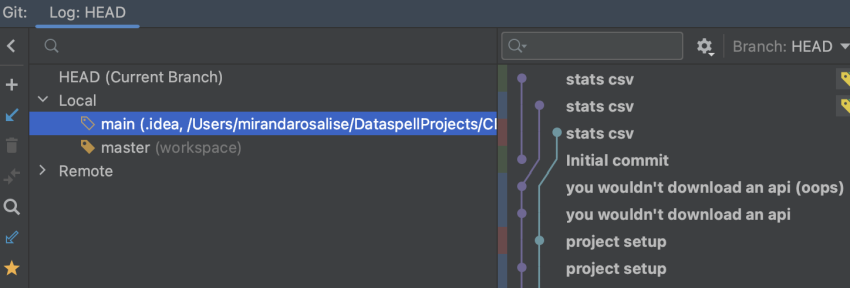
Looks like dataspell is a winner right? Look at the next two images and see if you can spot something off.


On the left, we have VSCode. And on the right, DataSpell. You might not catch it at first, but once I told you that these IDEs are working in identical file contexts, you might notice that VSCode lists each individual git repo within the workspace. DataSpell? Just the one. And you have no control on how to switch to the other(s).
Pretty annoying right? It frustrated me to no end during my company’s last hack-a-thon. And it’s this kind of lack of polish that really has put me off from adopting DataSpell as my daily driver. Add into all of this that you have to pay for DataSpell while VSCode is free, and, well.
It’s not really a competition anymore, is it?